Disaster Recovery (DR)
Similar to all other enterprise applications, Avantra should be capable of successful recovery in a disaster scenario. The speed at which you can recover in a disaster is completely down to the requirements of your organization and you should set up your Avantra environment to match these requirements.
Key influencing factors
RTO and RPO are key influencing factors in your Avantra DR considerations. The reason these two items are important is that they will directly influence your decisions around the architecture of your Avantra landscape.
RTO
Your recovery time objective (RTO) is the maximum acceptable time it takes to recover a system or service after a failure or disruption. It represents the time within which your organization should be able to restore its operations to a predefined acceptable level.
The key question here is how long your organization can operate without your Avantra environment functioning in a disaster scenario.
RPO
Your recovery point objective (RPO) is the maximum allowable amount of data loss that an organization is willing to tolerate in the event of a disaster or disruption. In other words, RPO specifies the point in time to which data must be recovered after an incident.
The key question you must consider for RPO is, when you do recover your Avantra system, what is an acceptable gap in data that you’re willing to accept in a disaster scenario.
DR Scenarios
|
For all HA and DR scenarios, it is vital that your Avantra server is set up with a DNS alias from the beginning and this alias is what is used for both user and agent access to the Avantra Server. If you use a raw IP address or the Avantra Server hostname, then you will have issues restoring agent connectivity to the Avantra server in a HA or a DR scenario. The fully qualified DNS alias should be configured in the Avantra server under the following configuration items (found in the Administration → Settings menu):
|
|
You should never run two sets of Avantra services at the same time on top of the same database as this can lead to data corruption. |
Scenario 1 - rebuild in 24 hours
If your RTO is 24 hours and your RPO is 24 hours, then you can comfortably stand up a new database server in the cloud, restore a database backup from the previous day and then restore a snapshot of your Avantra server from the previous day all within that 24 hour RTO.
The main requirement would only be to ensure that there is an off-site/out-of-region backup of your Avantra database and a daily snapshot of the Avantra server available during the disaster.
To invoke DR in this scenario, you would perform the following:
-
Create a new database instance and restore the previous days backup
-
Create a new Avantra server based on a snapshot from the previous day
-
Repoint the DNS alias for the Avantra server to the new DR Avantra server host
-
Reconfigure the DR Avantra server to use the new database instance in the file
/opt/avantra/.xandira/database.cfg -
Bring up the Avantra services on the DR server
-
Log in with the local avantra administrator user and update the SSO configuration (if required)
-
Wait for all Avantra agents to reconnect
Scenario 2 - fail over within 1 hour
If your RTO is 1 hour and your RPO is 10 minutes, then creating new databases and servers isn’t going to be easy to complete in that timeframe (even in the cloud), so an alternative setup is required.
In this case, you would have a cold-standby Avantra server node in an alternative data center/zone which has storage-level replication of the volume containing the application data on the filesystem (usually the folder /opt/avantra) along with a database instance that is being kept up to date via log shipping (or some other means).
To invoke DR in this scenario, you would perform the following:
-
Repoint the DNS alias for the Avantra server to the DR host
-
Reconfigure the DR Avantra server to use the DR database instance in the file
/opt/avantra/.xandira/database.cfg -
If using an OS or package manager provided Java runtime, ensure it is up to date with the latest supported version
-
Bring up the Avantra services on the DR server
-
Log in with the local avantra administrator user and update the SSO configuration (if required)
-
Wait for all Avantra agents to reconnect
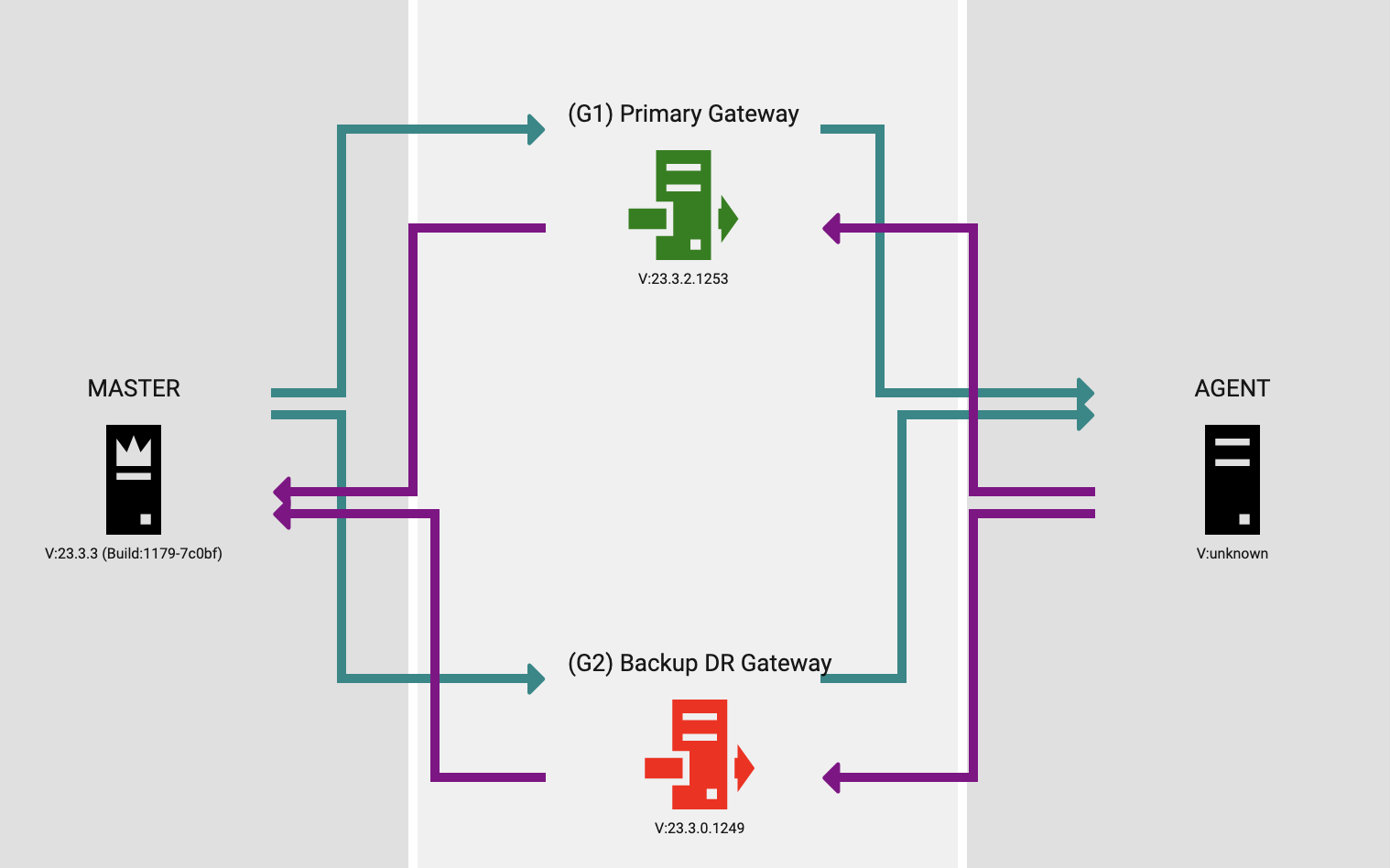
Agent connectivity during DR
If you are using the recommended approach of a DNS alias that can be repointed to a DR Avantra server host, then agent connectivity should largely be unaffected during a disaster. However, if you are using Agent Gateways through which remote agents communicate with the Avantra server, then you will need to consider backup routes that do not rely on nodes in the same location as the original Avantra server. The rule of thumb here is to always have a backup route when using Agent Gateways in an environment where DR is an important aspect.
Taking an example:
Resources:
-
Normal Operation
-
Avantra Server (A1)
-
Avantra Agent acting as a gateway (G1)
-
Monitored Server (S1)
-
-
DR Operation
-
Avantra Server (A2)
-
Avantra Agent acting as a gateway (G2)
-
If your monitored system (S1) uses the gateway (G1) to talk to the Avantra Server (A1) but the gateway (G1) is in the same data center as the Avantra server (A1) and is the ONLY route that the monitored system (S1) can use to communicate with Avantra, then in the event of a disaster affecting that data center, the monitored system will have no way to communicate with the Avantra Server (A1) even if it is restored to the DR environment (A2).
Instead, you should have a backup route configured that the monitored system (S1) can optionally use a secondary gateway (G2) which might be in the same data center as the disaster recovery Avantra Server (S2). This secondary route could largely remain unavailable (i.e. in cold-standby mode) unless required, but it at least will be immediately available for use during a DR scenario to begin handling incoming traffic from monitored systems.
Final thoughts on DR
Every environment is different
Depending on the infrastructure you use (Cloud, On-premises, Hosted) there are several ways you can configure DR for your environment and a large number of technologies you could use. The aim of this guide is not to provide step-by-step instructions for any one set of technologies or environment, but instead to illustrate the principals you will need to employ when designing and testing your own DR set up.
While we will happily review and advise on the best set up for your environment, we are not experts in all of the potential HA and DR technologies you could employ so please choose a set that your IT organization is already familiar with and knows how to use. This WILL make your life easier and create a more robust environment.
DR shouldn’t be theory
We strongly encourage you, after you have designed your DR setup, to test the invoking of your DR environment. Only when you have done an end-to-end DR test can you be certain that it will both work and fulfill the business needs. It may not work the first time and that is great as long as the first time is a test and you have the space to learn from it.